An 8.3B parameter GPT-2 from Nvidia which leverages model parallelism for training across 512 GPUs. The type of model parallel used is now known as tensor parallel and it involves splitting separable sequences of operations across multiple devices and gathering the shards at the end of the sequence.
Contributions:
- Tensor parallel scheme
- 76% scaling efficiency using 512 GPUs
- Careful placement of layer normalisation in BERT-like models is critical to achieving increased accuracies as the model grows
- Scaling the model size improves accuracies for both GPT-2 (studied up to 8.3B) type models and BERT (studied up to 3.9B) models (N.B. this paper predates scaling-laws by 5 months)
- SOTA results in test sets
The only surviving contribution is the tensor parallel scheme. Since BERT and GPT-2 are now considered obsolete in light of newer, larger models.
Figure 2 serves as a reminder of the construction of an encoder only Transformer:
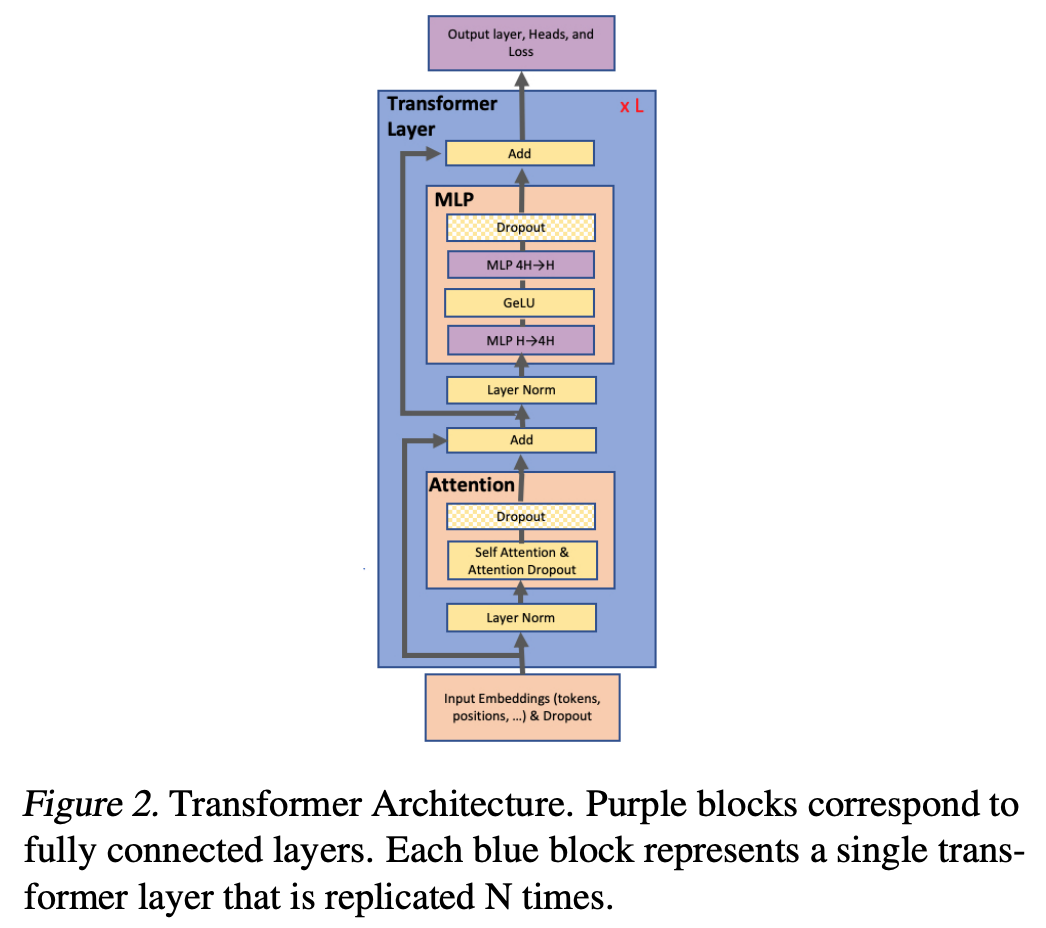
Figure 3 then shows how the compute is split across 2 GPUs (although and could scatter and gather across an arbitrary number of GPUs):
 The choice of dimension in the splitting of removes the need for a reduce because if they were split as follows:
The choice of dimension in the splitting of removes the need for a reduce because if they were split as follows:
Then you’d have the following problem because is non-linear:
However, when splitting as follows, you can output shards of that can be consumed directly by the next matrix multiplication:
The same technique is applied with the self-attention, as shown in Figure 3b. They also parallelise the output embedding projection across the vocabulary dimension (column-wise).
References