The following explanation of MoE models comes from the DeepSeekMoE paper.
A standard Transformer language model is constructed by stacking layers of standard Transformer blocks, where each block can be represented as follows:
where denotes the sequence length, denotes the self-attention module, denotes the Feed-Forward Network (FFN), are the hidden states of all tokens after the -th attention module, and is the output hidden state of the -th token after the -th Transformer block. For brevity, we omit the layer normalisation in the above formulations.
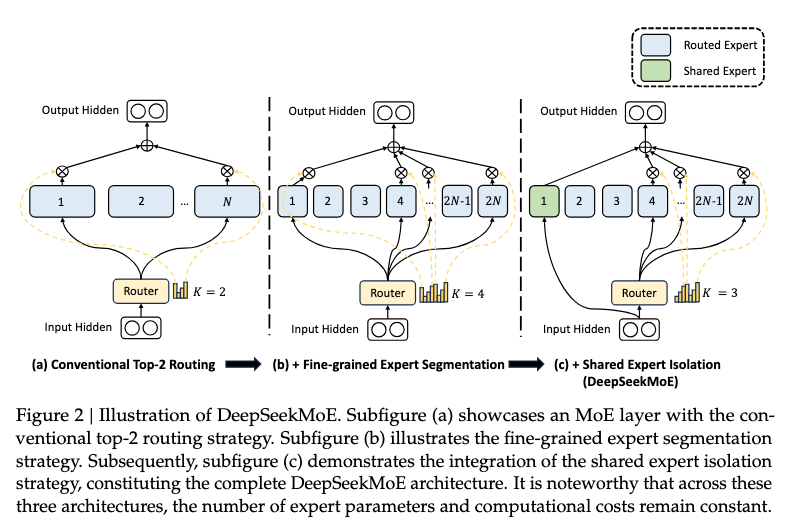
A typical practice to construct an MoE language model usually substitutes FFNs in a Transformer with MoE layers at specified intervals. An MoE layer is composed of multiple experts, where eah expert is structurally identical to a standard FFN. Then, each token will be assigned to one or two experts. If the -th FFN is substituted with an MoE layer, the computation for its output hidden state is expressed as:
where denotes the total number of experts, is the -th expert , denotes the gate value for the -th expert, denotes the token-to-expert affinity, denotes the set comprising highest affinity scores among those calculated for the -th token and all experts, and is the centroid of the -th expert in the -th layer. Note that is sparse, indicating that only out of gate values are non-zero. This sparsity property ensures computational efficiency within an MoE layer, i.e., each token will only be assigned to and computed in only experts. Also, in the above formulations, we omit the layer normalisation operation for brevity.
References