The DeepSeekMoE is a mixture-of-experts architecture that involves two principal strategies:
- finely segmenting the experts into ones and activating from them, allowing for a more flexible combination of activated experts
- isolating experts as shared ones, aiming at capturing common knowledge and mitigating redundancy in routed experts
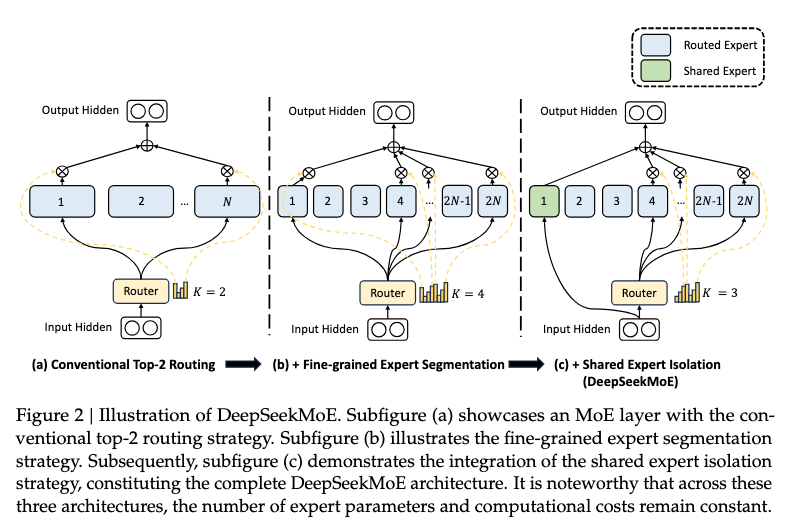
Fine-Grained Expert Segmentation
The idea here is that many smaller experts is better than few large experts. The rationale is that large experts are:
- be more likely to encounter a wide variety of knowledge
- therefore more likely to learn to generalise to this wide knowledge
With many small experts this wide variety of knowledge has more potential to be decomposed into the experts, allowing each expert to retain a high level of expert specialisation.
DeepSeekMoE:
- splits each expert into smaller experts by reducing the intermediate hidden dimension to times its original size
- increases the total experts times to keep the same memory cost, as illustrated Figure 2(b) where is doubled
- number of activated experts times to keep the same computational cost, as illustrated in Figure 2(b) where is doubled
The output of an MoE layer with fine-grained expert segmentation can be expressed as:
where the total number of expert parameters is equal to times the number of parameters in a standard , and denotes the total number of fine-grained experts. With the fine-grained expert segmentation strategy, the number of non-zero gates will also increase to .
Shared Expert Isolation
Certain tokens may require each expert to have some common knowledge. In conventional routing, multiple experts might acquire this common knowledge, resulting in redundancy in expert parameters. This redundancy can be mitigated by using dedicated shared experts to capture and consolidate this common knowledge.
To achieve this, experts are isolated to serve as shared experts. Each token will deterministically be assigned to these shared experts. The number of experts activated by the router is decreased by in order to maintain a constant computational cost, as illustrated in Figure 2(c) where is decreased by the number of shared experts.
Therefore, an MoE layer in the complete DeepSeekMoE architecture is formulated as follows:
Finally, in DeepSeekMoE the:
- number of shared experts is
- total number of routed experts is
- number of non-zero gates is
Load Balance Consideration
There are two main routing considerations when training an MoE model:
- If the same experts are always chosen, other experts are prevented from learning. This is called routing collapse
- If experts are distributed across multiple devices, load imbalance can exacerbate computation bottlenecks
In practice, a:
- small expert-level balance factor is used to mitigate the risk of routing collapse
- large device-level balance factor is used to promote balanced computation across devices
Expert-Level Balance Loss
where is a hyperparameter called expert-level balance factor, is equal to and is equal to for brevity. denotes the indicator function.
Device-Level Balance Loss
If we partition all routed experts into groups , and deploy each group on a single device, then device-level balance loss is computed as follows:
where is a hyperparameter called device-level balance factor.
References