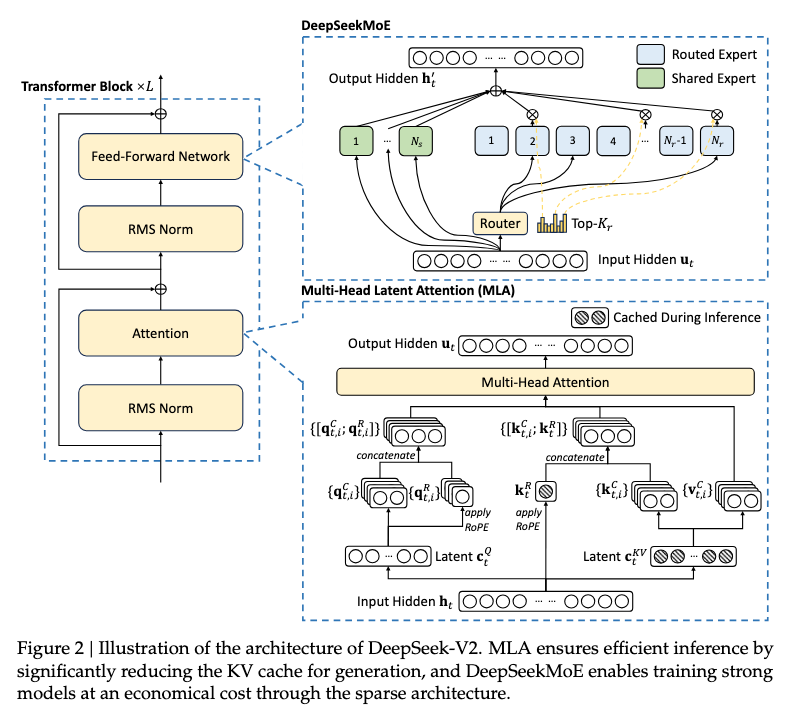
DeepSeek-V2 improves upon the DeepSeekMoE architecture by introducing MLA, an attention mechanism equipped with low-rank key-value join compression. Empirically, MLA achieves superior performance compared with MHA, and meanwhile significantly reduces the KV cache during inference, thus boosting the inference efficiency.
Comparison of KV Cache
where denotes the number of attention heads, denotes the dimension per attention head, denotes the number of layers, denotes the number of groups in GQA, and and denote the KV compression dimension and the per-head dimension of the decoupled queries and key in MLA, respectively.
For DeepSeek-V2, is set to and is set to . Therefore, MLA requires an amount of KV cache equal to GQA with only 2.25 groups, while achieving stronger performance than MHA.
References