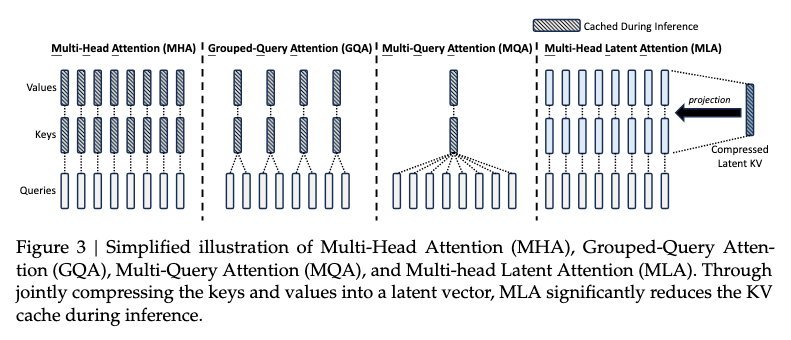
The use of kv-cache with MHA at inference time becomes the bottleneck for efficiency due to its large size.
Transclude of SDPA#a383c1
Transclude of MHA#2094e9
MLA, equipped with low-rank key-value joint compression, achieves better performance than MHA while requiring a significantly smaller amount of KV cache. The core of this can be expressed as:
where is the compressed latent vector for keys and values for a particular token; denotes the KV compression dimension; is the down-projection matrix; and are the up-projection matrices for keys and values, respectively.
During inference, MLA only needs to cache , so its KV cache has only elements, where denotes the number of layers. This method of compression is conceptually similar to LoRA, which is used for fine-tuning.
In addition, during inference, since can be absorbed into , and can be absorbed into , we even do not need to computes keys and values out for attention.
During training, low-rank compression can also be applied to the queries (although it cannot reduce the size of the KV cache):
where is the compressed latent vector for queries for a particular token; denotes the query compression dimension; , are the down-projection and up-projection matrices for queries, respectively.
Decoupled Rotary Position Embedding
As established by LLaMA (and used by DeepSeek), RoPE is an effective method of position embedding. However, RoPE is incompatible with MLA.
RoPE is position-sensitive for both keys and queries. If we apply RoPE for the keys (), the up-projection (*) will be coupled with a position sensitive RoPE matrix.
References