LoRA is an efficient method of index a foundation model for specific tasks.
When adapting to a specific task, pre-trained language models have low “intrinsic dimension” and can still learn efficiently despite a random projection to a smaller subspace. LoRA exploits this by freezing the pre-trained weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, as shown in Figure 1 from the paper:
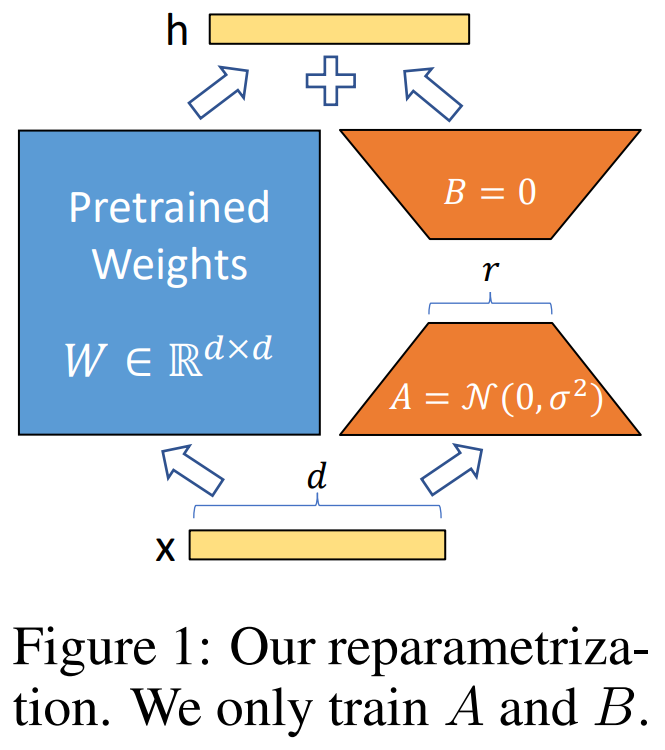
For a pre-trained weight matrix , we constrain its update by representing the latter with a low-rank decomposition , where , , and the rank . During training, is frozen and does not receive gradient updates, while and contain trainable parameters. Note both and are multiplied with the same input, and their respective output vectors are summed coordinate-wise. For , our modified forward pass yields:
As shown in Figure 1, A has Gaussian initialisation and B is zero initialised.
References