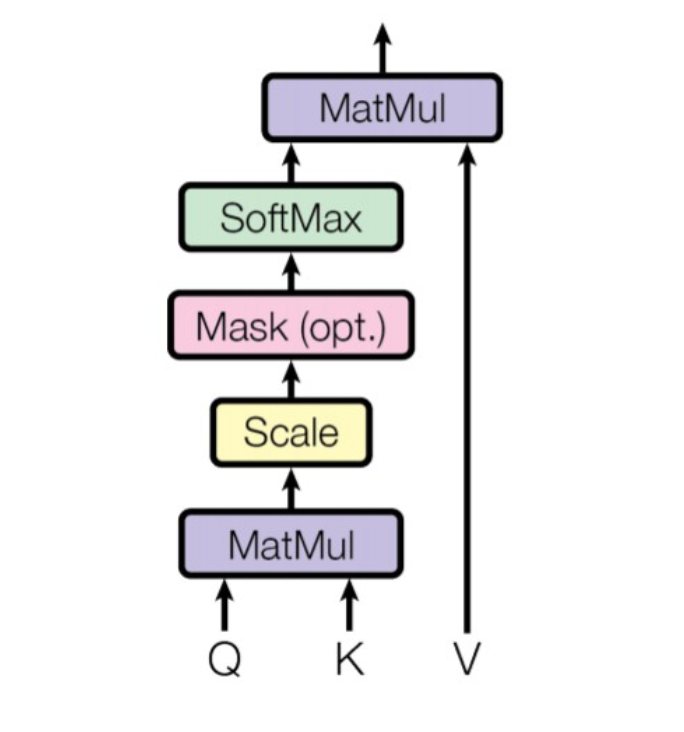
Scaled dot-product attention is an attention mechanism where the dot products are scaled down by . Formally we have a query , a key and a value and calculate the attention as:
If we assume that and are -dimensional vectors whose components are independent random variables with mean and variance , then their dot product, has mean and variance . Since we would prefer these values to have variance , we divide by . We then apply softmax to the attention scores so that they are transformed into a set of positive, normalised weights that sum to 1.
References