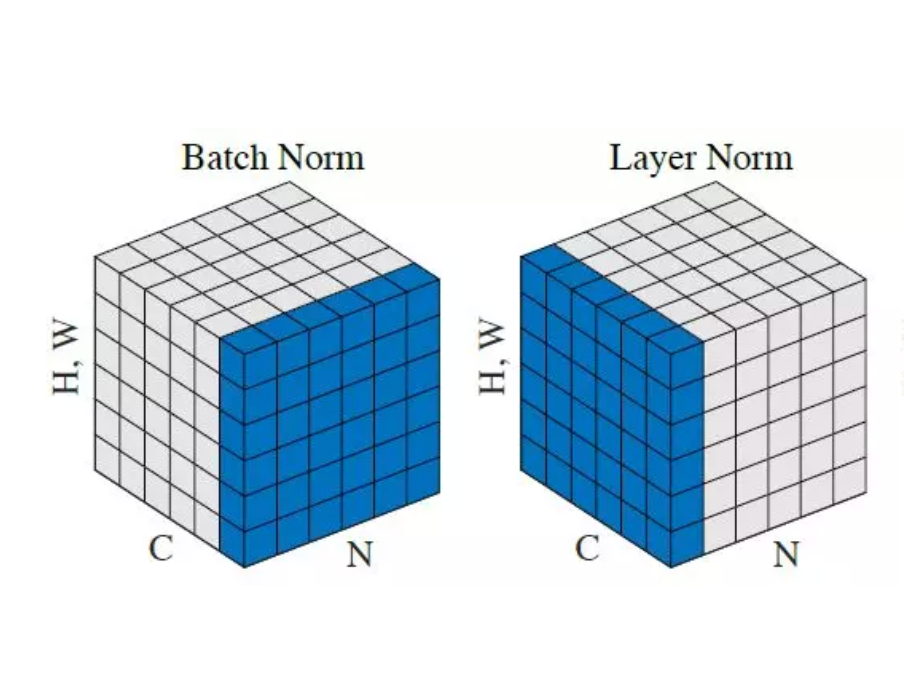
Unlike batch-norm, layer normalisation directly estimates the normalisation statistics from the summed inputs to the neurons within a hidden layer so the normalisation does not introduce any new dependencies between training cases. It works well for RNN and improves both the training time and the generalisation performance of several existing RNN models. More recently, it has been used with index models.
We compute the layer normalisation statistics over all the hidden units in the same layer as follows:
where denotes the number of hidden units in a layer. Under layer normalisation, all the hidden units in a layer share the same normalisation terms and , but different training cases have different normalisation terms. Unlike batch-norm, layer normalisation does not impose any constraint on the size of the mini-batch and it can be used in the pure online regime with batch size 1.
References